
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 |
- 브루트포스알고리즘
- 사칙연산
- 백준알고리즘
- 정수론
- 이분탐색
- 이진탐색
- 프로그래머스sql
- 논문구현
- C
- SQL
- 정렬
- 자료구조
- 해시를사용한집합과맵
- 문자열
- Image Classification
- 구현
- 프로그래머스연습문제
- MySQL
- 프로그래머스코딩테스트
- 백준
- C++
- 논문리뷰
- C언어
- 소수판정
- 큐
- 그리디
- 수학
- 그리디알고리즘
- 프로그래머스
- 다이나믹프로그래밍
- Today
- Total
초보 개발자의 이야기, 릿허브
[논문리뷰] NeRF (Representing Scenes as Neural Radiance Fields for View Synthesis) 본문
[논문리뷰] NeRF (Representing Scenes as Neural Radiance Fields for View Synthesis)
릿99 2023. 6. 19. 18:02NeRF
https://www.matthewtancik.com/nerf
NeRF: Neural Radiance Fields
A method for synthesizing novel views of complex scenes by optimizing an underlying continuous volumetric scene function using a sparse set of input views.
www.matthewtancik.com
1. Introduction
NeRF, Representing Scenes as Neural Radiance Fields for View Synthesis는
3D 장면을 재구성하는 새로운 방법 중 하나로 떠오른 View Synthesis 모델입니다.
사실, 대부분 사람들이 NeRF는 2D 이미지를 3D로 바꾸는 모델로 알고 있지만, 엄밀히 이야기하자면 다릅니다.
NeRF는 객체를 여러 각도에서 촬영한 여러 이미지들을 입력으로 사용하여
새로운 시점에서의 이미지를 생성하는 모델입니다.
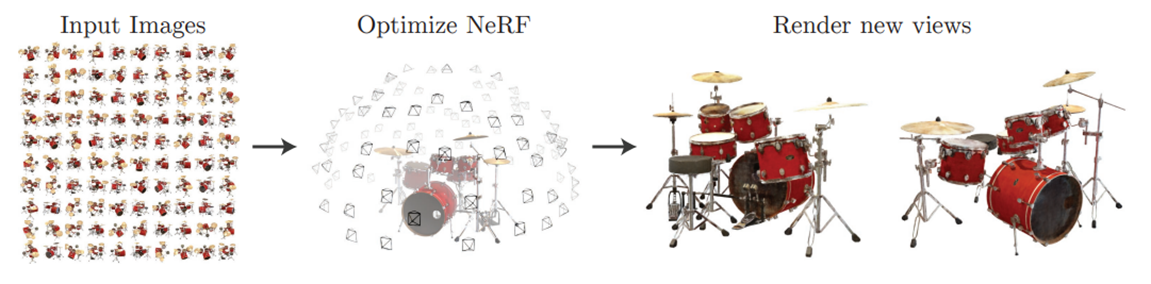
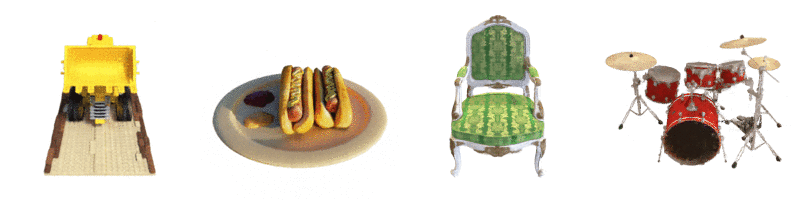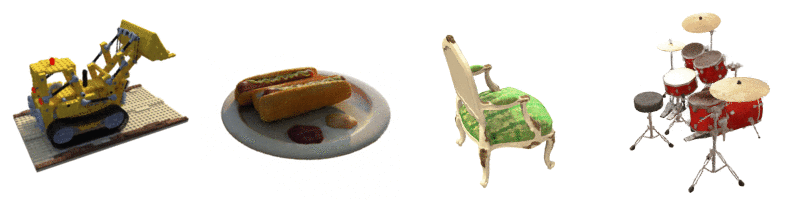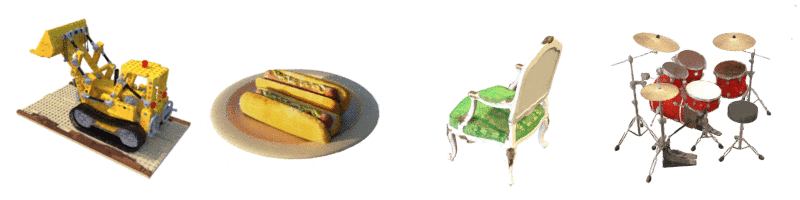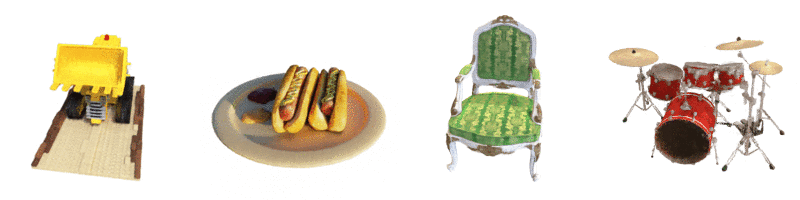
위와 같이, NeRF에 다양한 방향에서의 드럼의 이미지를 입력으로 부여하면,
입력 세트에 없는 새로운 시점에서의 드럼 이미지를 생성할 수 있습니다.
즉, 예를 들어, 한 객체의 앞, 뒤, 좌, 우 방향에서 촬영한 몇 장의 이미지를 제공하면,
NeRF는 나머지 시점에서의 이미지를 생성할 수 있습니다.
이러한 모든 이미지를 결합하면, 객체를 3D로 보는 것과 같은 효과가 나타나는 것입니다.
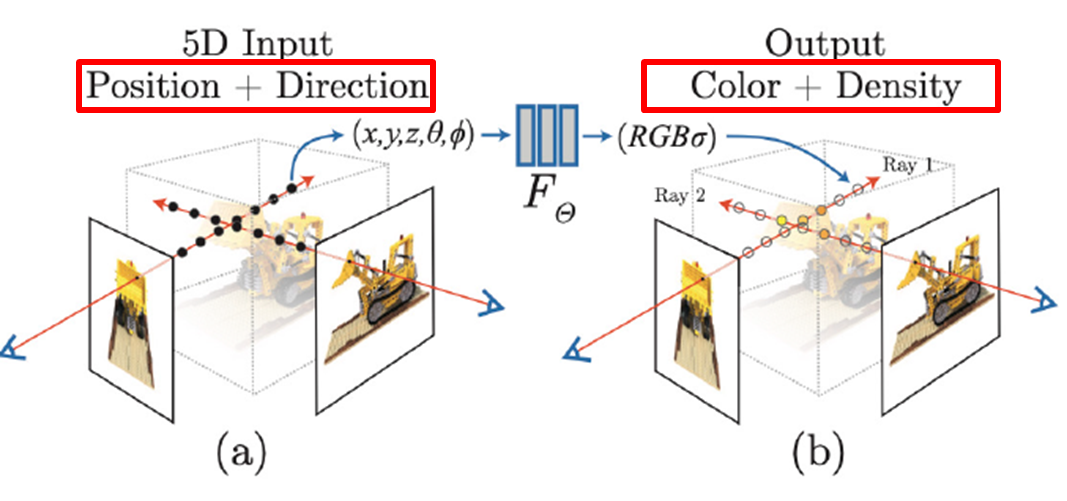
NeRF의 가장 핵심적인 아이디어는 3D 장면을 연속적인 5차원의 함수로 표현하는 것입니다.
이 함수는 5차원의 좌표 spatial location (x,y,z), viewing direction (θ,ϕ) 를 입력으로 받아
해당 지점에서의 RGB color (r,g,b), and volume density (σ)를 반환하는 Fully-connected network입니다.
여기서, 입력에 해당하는 3D spatial location (x, y, z)는 관찰 지점(시점),
2D viewing direction (θ,ϕ)는 객체를 바라보는 각도를 나타냅니다.
2. NeRF
2.1. Neural radiance field scene representation
앞서 언급한대로, NeRF는 3D spatial location과 2D viewing direction으로 구성된 5차원 좌표를 입력으로 받아,
RGB color와 volume density를 출력합니다.
NeRF는 neural network architecture를 이용하여 이 5차원 함수를 모델링하며,
서로 다른 시점에서 촬영한 대규모 이미지 세트를 사용하여 훈련됩니다.
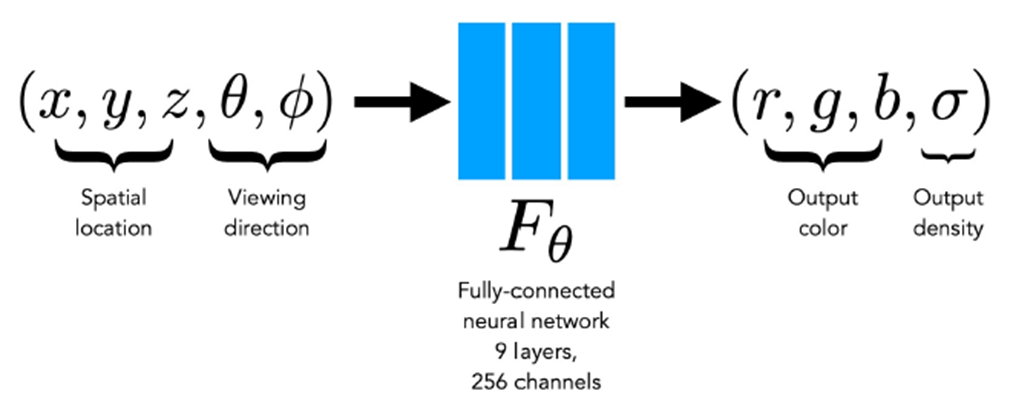
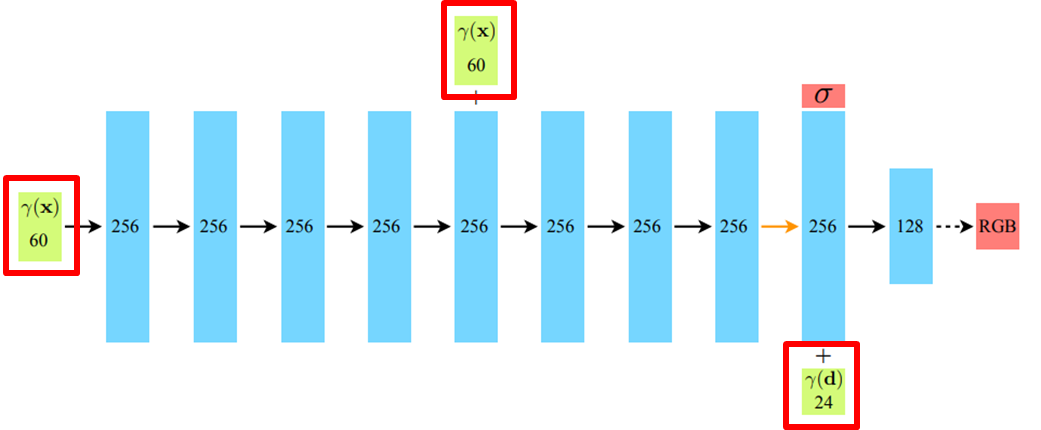
아래 그림은 NeRF의 네트워크 구조를 나타낸 그림으로, 총 9개의 레이어로 구성됩니다.
이 그림에서 주목해야 할 것은, spatial loaction 'x'와 viewing direction 'd'가 함께 입력으로 제공되지 않는다는 점입니다.
NeRF는 먼저 객체의 spatial location (x, y, z)만을 8개의 레이어에 통과시켜, 객체의 volume density 'σ'를 예측합니다.
아래 그림에서 왜 입력 layer의 차원이 각각 60, 24인지는 차후 설명드리겠습니다.
객체의 spatial location이 이러한 8개의 레이어를 통과하면서,
객체의 volume density 'σ'와 함께 256개의 feature vector가 생성됩니다.

8개의 레이어를 통과한 feature vector는 이후 viewing direction 'd'와 결합하여 최종 레이어의 input으로 사용됩니다.
아래 그림이 이를 나타낸 그림으로, viewing direction 'd'와 feature vector의 결합 정보를 활용하여 color 'c'를 예측합니다.

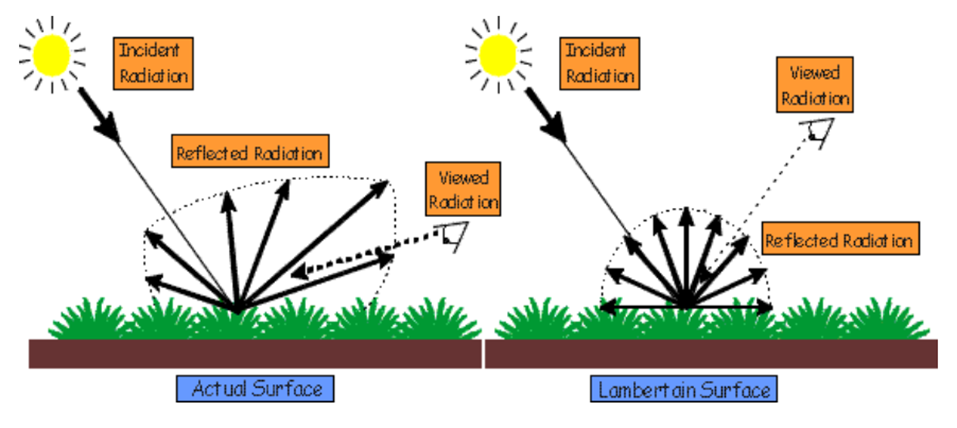
이렇듯 레이어를 입력을 2가지로 분류하여 학습하는 이유는 바로, 비램버시안 효과(Non-Lambertian Effect) 때문입니다.
비램버시안 효과란, 관찰 방향에 따라 색상과 반사율이 달라지는 현상을 말합니다.
우리가 보는 대부분의 물체들은 비램버시안 효과를 가지고 있습니다.
아래 그림에서 좌측은 실제 비램버시안 표면인 물체를 나타내고, 우측은 램버시안 표면을 나타냅니다.
실제 세계에서는, 비램버시안 효과와 같이 관찰 각도를 변경하면 특정 부분의 색상이 변화합니다.
따라서, 이를 NeRF의 구조로 돌아와 생각해보면, density 값은 spatial location 'x'에,
RGB 값은 spatial location 'x', viewing direction 'd', density '𝜎' 에 종속되기 때문에
이전 그림과 같이 분리된 입력을 가진 구조를 갖게됩니다.
2.2. Volume rendering with radiance fields
NeRF의 네트워크 구조를 살펴보았으니, 이제 NeRF의 렌더링 과정과 네트워크에 대해 살펴보겠습니다.
Volume rendering은 네트워크에서 얻은 RGB 색상 'c'와 density '𝜎'를 결합하여, 이를 단일 픽셀로 변환하는 과정입니다.
이 과정을 이해하기 전에 알아야 할 개념이 있는데, 바로 'ray'입니다.
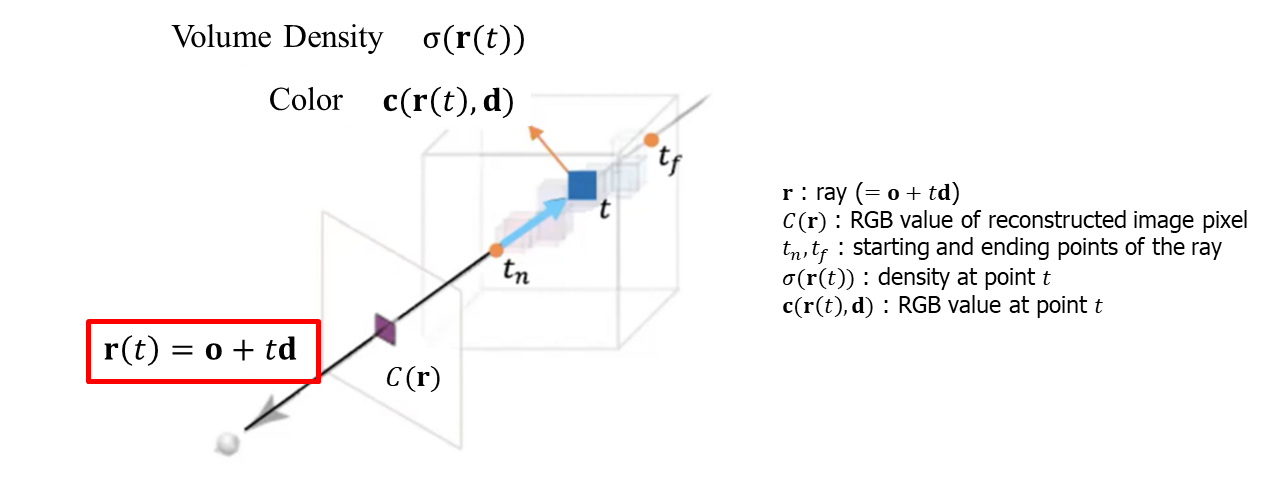
ray는 카메라의 위치에서 3D 객체의 한 점을 바라볼 때 형성되는 직선입니다.
ray는 카메라의 지점 'o'로부터 특정 방향 'd'으로 't'만큼 이동한 점들의 집합입니다.
아래 이미지의 검은색 선이 바로 camera ray입니다.
이렇듯, 카메라의 위치 'o'와 viewing direction 'd'가 결정된다면, 아래 그림과 같은 방정식을 통해 ray를 계산할 수 있습니다.

앞서 설명한 ray를 이해했다면, 밀도 density와 ray와의 관계에 대해 이해해야합니다.
density는 간단히 말하자면, 투명도(transparency)의 반대 개념입니다.
density(밀도)가 높다면, 해당 물체는 투명도가 낮아 불투명할 것이고,
density(밀도)가 낮다면, 반대로 투명도가 높아 투명할 것입니다.
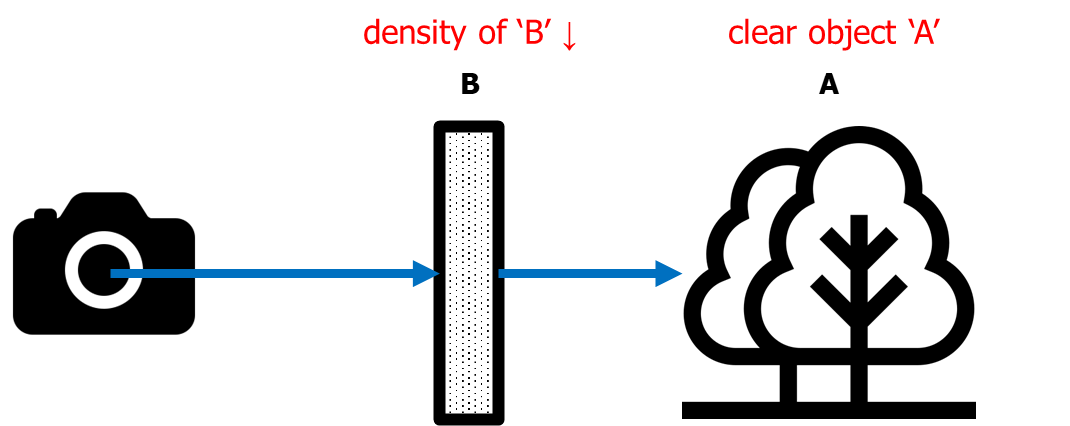
아래 그림과 같이, 나무 'A'를 촬영하려고 할 때 물체 'B'가 그 앞을 막고 있다고 가정해봅시다.
여기서 우리가 촬영하려고 하는 나무 'A'는, 'B'의 밀도에 따라 명확하게 촬영될 수도, 그렇지 않을 수도 있습니다.
만약 'B'의 밀도가 그림과 같이 낮다면, 즉 투명하다면, A 나무는 깔끔하게 촬영될 것입니다.
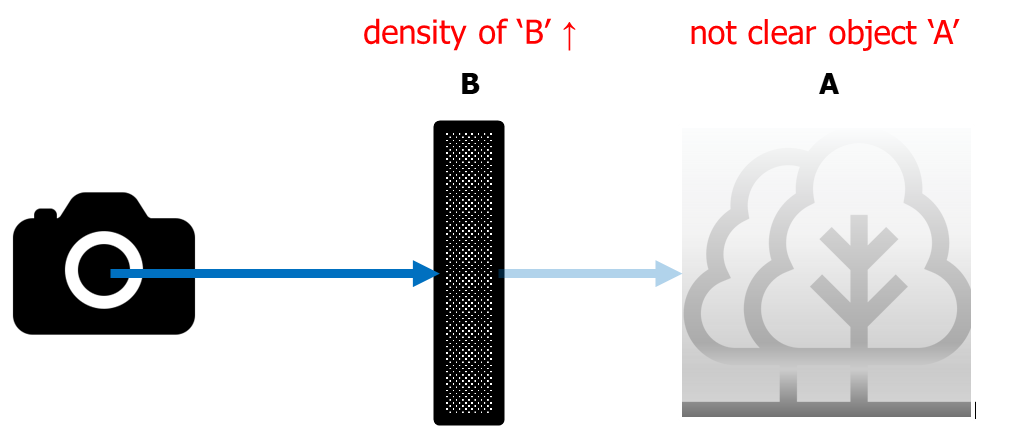
반면, 아래 그림처럼 'B'가 높은 밀도를 가진다면, 즉 'B'가 투명하지 않다는 것을 의미합니다.
따라서 나무 A는 잘 보이지 않을 것입니다.
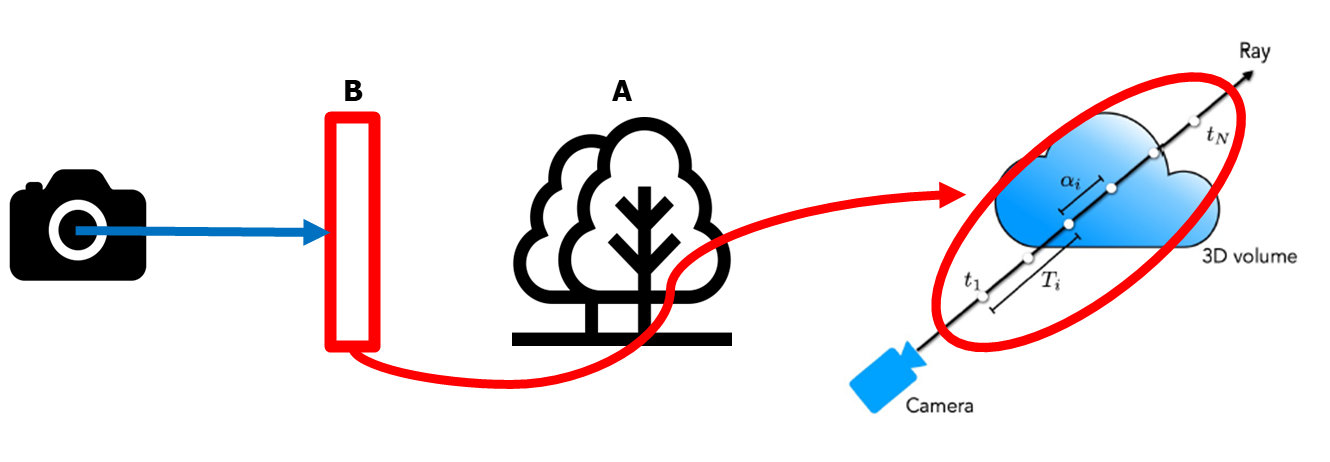
다시 ray로 돌아가 보겠습니다.
아래 그림과 같이 ray 위의 모든 각각의 점 't'는 B와 같은 역할을 합니다.
이러한 하나의 ray 위의 모든 점들의 density에 따라, 결과 이미지의 픽셀 값은 증가하거나 감소할 수 있습니다.
본 논문의 저자들은 ray 위의 모든 점들의 RGB 값과 density의 가중합(weighted sum)을 계산했습니다.
다시 말해, 점 't'의 밀도가 높다는 것은 해당 점이 투명하지 않고 물체가 잘 보이지 않는다는 의미이므로,
점 't'에 대한 가중치는 작은 값을 갖습니다.
반대로, 't'의 밀도가 낮다는 것은, 투명하기때문에 뒤의 물체가 쉽게 볼 수 있다는 의미이므로,
해당 점 't'의 가중치는 높게 설정됩니다.
앞선 내용을 모두 정리한 식이 바로 아래 그림의 식입니다.
'r'은 하나의 ray, 'tn', 'tf'는 각각 ray가 물체를 통과할 때의 시작점과 끝점을 나타냅니다.
'c'와 'σ'는 각각 점 't'에서의 색상과 밀도(density)를 나타냅니다.
T(t)는 특정 점 't' 앞에 있는 점들의 밀도 합을 나타내며, 밀도 σ(시그마)의 적분을 통해 얻어집니다.
여기서, (-) 기호는 이 값이 크면 원하는 물체가 점 't' 앞에 있는 점들에 의해 가려진다는 것을 나타냅니다.
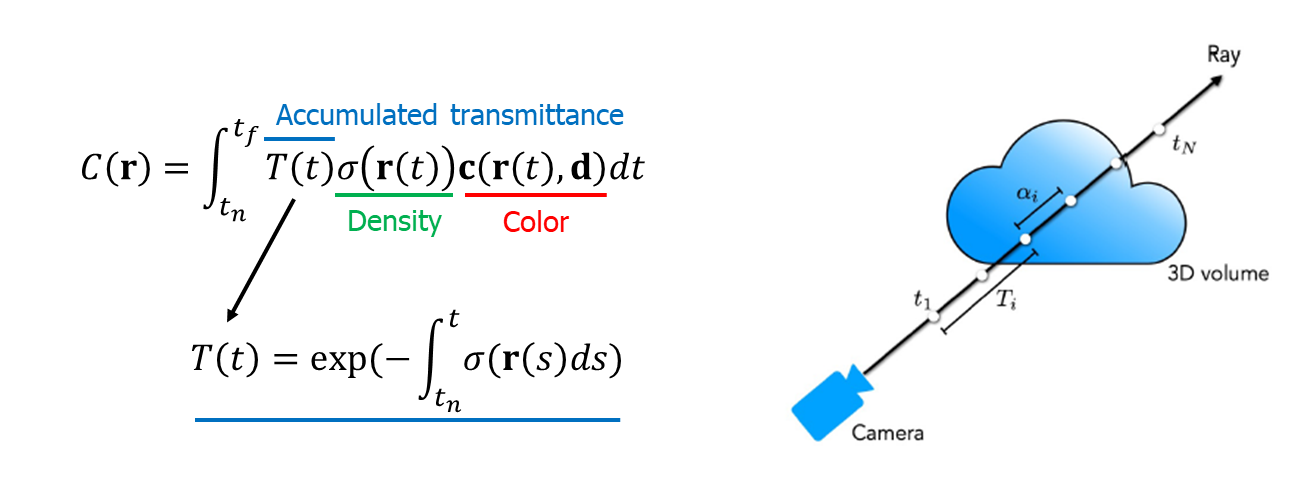
ray는 직선이고, 사실 이 직선 상에는 무수히 많은 점들이 존재합니다.
만약 이 무수히 많은 점들에 대해 앞선 계산을 모두 수행한다면, 너무 시간이 많이 소요될 것입니다.
따라서 본 논문의 저자들은 ray 상에서 몇 개의 점을 샘플링하고 추출하는 방법을 사용했습니다.
그러나 ray 위의 점들을 무작위로 선택할 경우, 한 부분에서 너무 많은 점들이 선택되거나 하나의 점도 선택되지 않을 수 있습니다.
따라서 저자들은 ray를 'n'개의 동일한 부분으로 분할하고, uniform 하게 sampling 되도록 했습니다.
이에 따라 변형된 식은 아래와 같습니다.

2.3. Optimizing a neural network radiance field
앞선 설명들을 통해 NeRF의 volume rendering 과정에 대해 알아보았으니,
이제 NeRF에서 사용되는 추가적인 구조 및 기법에 대해 알아보겠습니다.
2.3.1. Positional encoding
NeRF에서 사용한 첫 번째 추가적인 기법은 바로 Positional encoding 입니다.
Positional encoding은 NeRF의 네트워크가 high frequency(detail) 영역까지 학습할 수 있도록 하는 기법입니다.
사실 이 기법은 새로운 것은 아니고, low dimension 입력 값을 high dimensional space로 mapping 할 때,
네트워크 입력 전에 high frequency function을 이용하면 효과적이라는 이전 연구 결과를 차용한 것입니다.
예를 들어, 값 1과 2가 MLP(Multi-Layer Perceptron) 레이어를 통과하면 매우 유사한 값이 나오게 됩니다.
이는 레이어가 가중치 합인데, 값의 차이가 크지 않으면 결과 값도 매우 유사해지기 때문입니다.
이를 해결하기 위해 Positional encoding을 사용하여 고차원으로 변환합니다.
아래 그림은 Positional encoding의 식과 결과로,
그림에서 볼 수 있듯, Positional encoding이 포함되지 않은 경우 고해상도를 잘 표현할 수 없지만,
Positional encoding을 사용하면 고해상도 부분이 잘 표현되는 것을 확인할 수 있습니다.
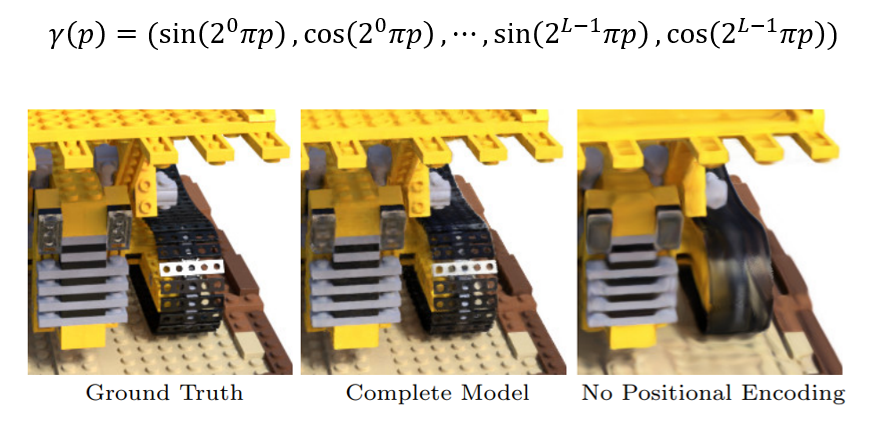
앞서 설명한대로, Positional encoding에는 사인(sin)과 코사인(cos) 함수가 사용되며,
이로 인해 dimension이 2L배로 증가합니다.
본 논문에서는 위치 'x'와 viewing direction 'd'에 대해 다른 크기의 L을 적용했습니다.
위치에는 viewing direction보다 더 많은 정보가 있기 때문에 위치에는 L=10을 사용하고,
viewing direction에는 L=4를 사용했습니다.(이 값은 논문의 저자들에 의해 결정)
아래 그림의 빨간 상자를 살펴보면, Positional encoding을 통해 각각 60과 24의 차원으로 변환된 것을 볼 수 있습니다.
2.3.2. Hierarchical volume sampling
NeRF에서 사용한 두 번째 추가적인 기법은 Hierarchical volume sampling 입니다.
이전 과정을 살펴보면 하나의 네트워크만 필요한 것처럼 보이지만, 사실 논문에서는 두 개의 네트워크를 사용합니다.
바로 coarse 네트워크와 fine 네트워크 입니다.
각각의 네트워크는 coarse한(전체적인) 정보와 fine한(세부적인) 정보를 다루며,
ray 위의 점 t를 어떻게 샘플링하는지에 따라 차이가 있습니다.
샘플링을 수행할 때, ray 위의 한 점이 객체에서 선택될 수도 있고, 아무것도 없는 지점이 선택될 수도 있습니다.
저자들은 이 아이디어에서 출발하여, 아무것도 없는 지점보다는
객체가 존재하는 지점에서 추가적인 학습을 수행하는 것이 효과가 더 좋을 것이라고 생각했습니다.
따라서, 앞서 이야기한 두 개의 네트워크가 사용됩니다.
첫 번째로, coarse 네트워크는 전체 레이에서 샘플링을 통해 학습을 수행합니다.
그리고 fine 네트워크는 학습된 결과 중에서 밀도 값이 큰 부분만 선택하여 추가적인 학습을 위해 재샘플링을 수행합니다.
최종 결과는 이 두 개의 네트워크를 결합하여 얻어집니다.

Hierarchical volume sampling에서 coarse 네트워크는 이전에 설명한대로 모든 레이에서 균일하게 t를 샘플링하여 학습을 수행합니다.
이렇게 샘플링된 점들은 coarse 네트워크를 통과하게 됩니다.
그리고 이 coarse 네트워크에서 얻은 가중치 값은 다시 샘플링을 위한 확률 분포로 사용됩니다.
이렇게 재샘플링된 점들은 fine 네트워크의 학습에 사용됩니다.
loss function 및 동작과정은 아래와 같습니다.
아래 식의 첫 번째 부분(연두색)은 coarse 네트워크, 두 번째 부분(주황색)은 fine 네트워크의 loss에 해당합니다.
NeRF는 일부 학습 데이터로부터 학습을 수행하고, 즉시 새로운 시점에서 이미지를 생성합니다.
이 새롭게 생성된 이미지는 나머지 학습 데이터와 비교하게되는데,
이 때, 나머지 데이터는 Ground Truth와 동일한 역할을 하며, 두 이미지 간의 손실을 비교하여 역전파를 통한 학습을 수행합니다.
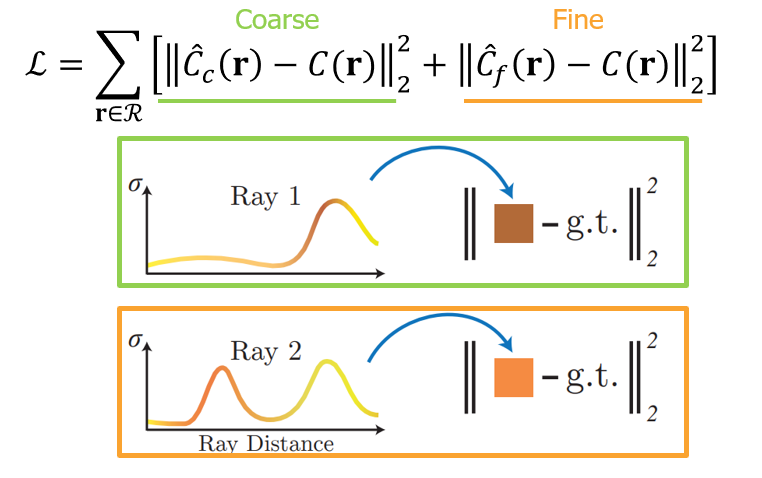
3. Experiment results
다음으로 NeRF의 실험 결과입니다.
NeRF의 저자들은 두 개의 데이터셋을 기반으로 모델을 평가했습니다.
첫 번째로, synthetic dataset입니다.
해당 데이터셋은 DeepVoxels dataset과 generated dataset으로 나뉘며, 아래 그림과 같습니다.

두 번째로, real-world dataset입니다.
해당 데이터셋은 말 그대로 실제 환경에서 찍힌 이미지를 이용한 데이터셋으로, 아래 그림과 같습니다.

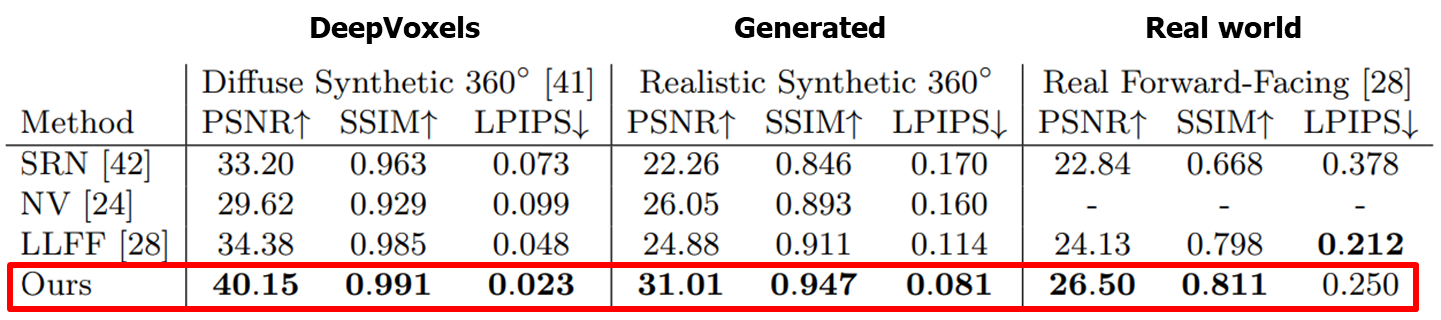
이전에 언급한 바와 같이, NeRF의 저자들은 2개의 데이터셋(세부적으로는 3개)을 테스트했습니다.
Diffuse Synthetic는 DeepVoxels 데이터셋을 사용한 synthetic dataset이며,
Realistic Synthetic은 generated synthetic dataset입니다.
마지막으로, Real Forward-Facing은 real-world dataset입니다.
아래 표와 같이 거의 모든 데이터셋과 평가 지표에서 NeRF가 기존의 방법들보다 우수한 성능을 보였으며,
그림에서도 볼 수 있듯, 다른 기법들에 비해 high frequency 성분을 잘 나타내는 것을 확인 할 수 있습니다.


4. Conclusion
NeRF는 다양한 방향에서 촬영된 이미지를 입력으로 받아, 다른 시점에서의 이미지를 반환하는 기술로,
현실적인 3D 모양을 생성 및 렌더링하는데 자주 사용됩니다.
NeRF는 이러한 고품질의 3D 재구성 및 렌더링 기술을 제공하지만, 명백한 단점이 있습니다.
NeRF는 단 하나의 장면을 최적화하기 위해 약 100에서 300번의 iteration을 필요로 하며, 실제로는 1~2일이 소요됩니다.
이렇게 NeRF는 매우 큰 계산 비용과 메모리를 요구합니다.
최근에는 이러한 단점을 극복하기 위해 FastNeRF 등의 방법들이 제안되기도 했습니다.
Reference
https://modulabs.co.kr/blog/nerf-from-2d-to-3d/
NeRF: 2D 이미지를 3D로 바꿔준다고요?
요즘 인공지능 분야에서 핫한 분야가 무엇일까요? 아마도 NERF가 아닐까 싶습니다. NeRF(Neural radiance Fields)는 2D 이미지를 3D로 변환해주는 모델입니다. 이번 콘텐츠에서는 NeRF에 대해 알아보겠습니
modulabs.co.kr
최초의 연속적인 신경 장면 표현- NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis - cobslab
안녕하세요 콥스랩(COBS LAB)입니다. 오늘 소개해 드릴 논문은 ‘NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis’입니다. 해당 내용은 유튜브 ‘딥러닝 논문 읽기 모임’ 중 ‘NeRF’ 영상
cobslab.com
https://woochan-autobiography.tistory.com/933#3.1
Paper Review - NeRF (Representing Scenes as Neural Radiance Fields for View Synthesis)
NeRF 논문 리뷰 포스팅입니다. 3D Vision 공부를 시작한 이후 첫 논문 리뷰 및 정리인 만큼 잘못된 부분이 많을 수 있으니, 잘못된 부분은 언제든 코멘트 해주시기 바랍니다. Introduction NeRF는 어떤 물
woochan-autobiography.tistory.com


