
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 |
- SQL
- 그리디알고리즘
- 다이나믹프로그래밍
- 구현
- 논문구현
- 정수론
- C언어
- C++
- C
- 소수판정
- 큐
- 정렬
- 사칙연산
- 프로그래머스
- 프로그래머스연습문제
- 그리디
- 논문리뷰
- 백준알고리즘
- 브루트포스알고리즘
- 문자열
- 프로그래머스sql
- 해시를사용한집합과맵
- 자료구조
- 백준
- 이분탐색
- 프로그래머스코딩테스트
- Image Classification
- MySQL
- 수학
- 이진탐색
- Today
- Total
초보 개발자의 이야기, 릿허브
[C++] 백준 2941번 크로아티아 알파벳 본문
1. 문제이해
https://www.acmicpc.net/problem/2941
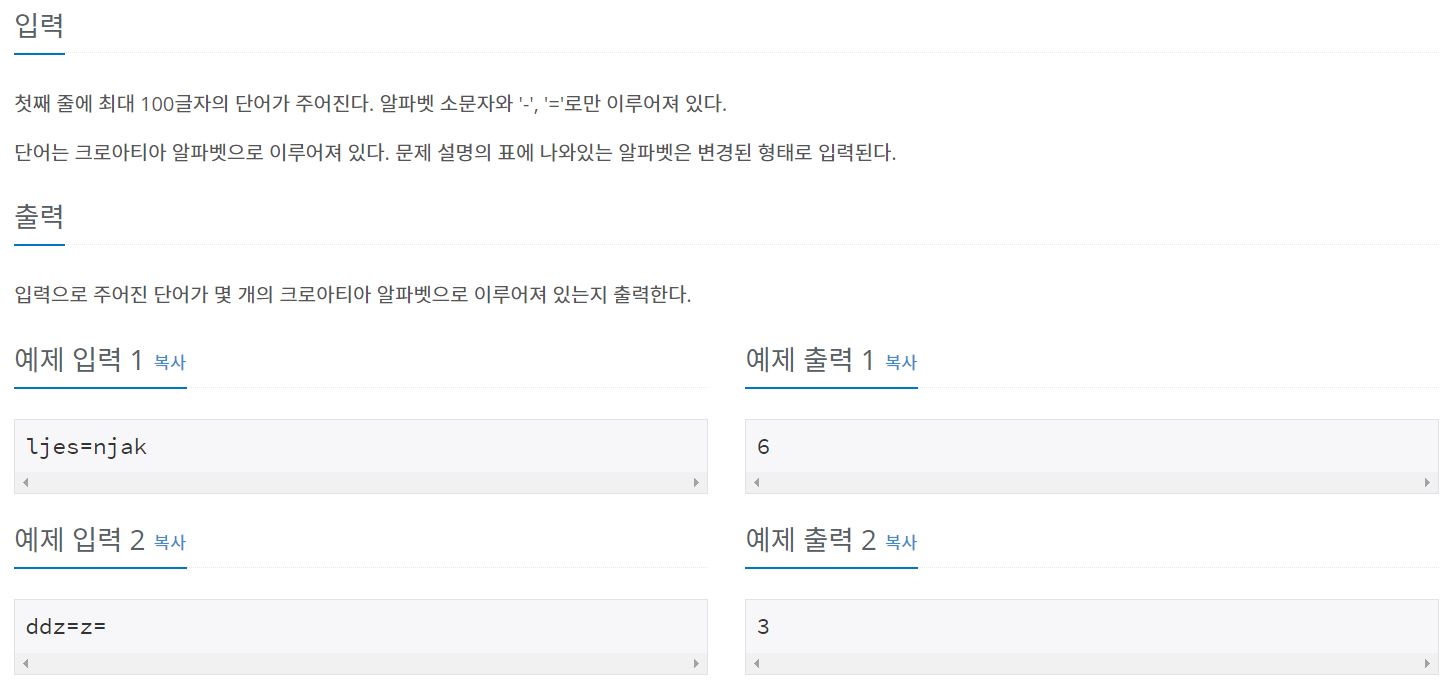
2941번: 크로아티아 알파벳
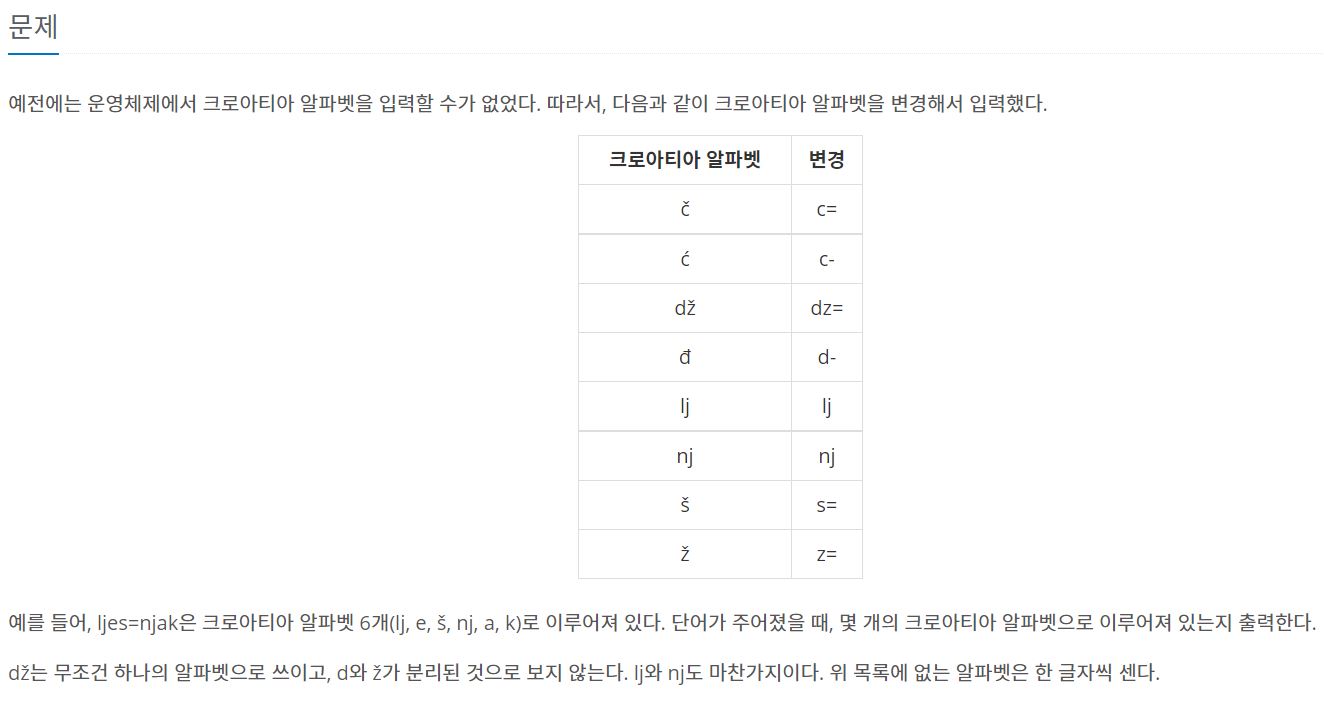
예전에는 운영체제에서 크로아티아 알파벳을 입력할 수가 없었다. 따라서, 다음과 같이 크로아티아 알파벳을 변경해서 입력했다. 크로아티아 알파벳 변경 č c= ć c- dž dz= đ d- lj lj nj nj š s= ž z=
www.acmicpc.net
크로아티아 알파벳의 갯수를 구하는 알고리즘을 구현하는 것이 목표이다.
크로아티아 알파벳 중 특수한 경우 (ex. c=, c-, dz=...) 는 위의 표와 같으며,
이를 하나의 크로아티아 알파벳으로 세고,
나머지 알파벳들을 세어 총 갯수를 구하는 알고리즘이다.
2. 문제풀이
크로아티아 알파벳의 갯수를 구하면 되는 비교적 간단한 문제이다.
문제 이해 부분에서 말한 것과 같이, 위의 8가지 특수한 크로아티아 알파벳의 경우를 따로 정의해 이를 카운트하고,
다른 알파벳의 경우에는 그냥 세어주면 되는 것이다.
3. 소스코드
#include <iostream>
#include <algorithm>
#include <string>
using namespace std;
int main() {
int count = 0;
string alphabet; // 크로아티아 알파벳 문자열 받기
cin >> alphabet;
// 크로아티아 알파벳인 경우 카운트
for (int i = 0; i < alphabet.size(); i++) {
// 1. c=
if (alphabet[i] == 'c' && alphabet[i + 1] == '=') {
alphabet[i] = '0';
alphabet[i + 1] = '0';
count++;
i++;
}
// 2. c-
else if (alphabet[i] == 'c' && alphabet[i + 1] == '-') {
alphabet[i] = '0';
alphabet[i + 1] = '0';
count++;
i++;
}
// 3. dz=
else if (alphabet[i] == 'd' && alphabet[i + 1] == 'z' && alphabet[i + 2] == '=') {
alphabet[i] = '0';
alphabet[i + 1] = '0';
alphabet[i + 2] = '0';
count++;
i += 2;
}
// 4. d-
else if (alphabet[i] == 'd' && alphabet[i + 1] == '-') {
alphabet[i] = '0';
alphabet[i + 1] = '0';
count++;
i++;
}
// 5. lj
else if (alphabet[i] == 'l' && alphabet[i + 1] == 'j') {
alphabet[i] = '0';
alphabet[i + 1] = '0';
count++;
i++;
}
// 6. nj
else if (alphabet[i] == 'n' && alphabet[i + 1] == 'j') {
alphabet[i] = '0';
alphabet[i + 1] = '0';
count++;
i++;
}
// 7. s=
else if (alphabet[i] == 's' && alphabet[i + 1] == '=') {
alphabet[i] = '0';
alphabet[i + 1] = '0';
count++;
i++;
}
// 8. z=
else if (alphabet[i] == 'z' && alphabet[i + 1] == '=') {
alphabet[i] = '0';
alphabet[i + 1] = '0';
count++;
i++;
}
}
// 0 이 아닌 부분 카운트
for (int j = 0; j < alphabet.size(); j++) {
if (alphabet[j] != '0') {
count++;
}
}
cout << count;
}코드가 길어보이지만 사실 간단하다.
단어를 입력받은 뒤, 특수한 크로아티아 알파벳의 경우가 8가지여서, 8번의 if문을 통해 경우를 나누어주었다.
입력받은 단어의 앞에서부터 확인해나가면서, 위 8가지 경우와 같은 단어가 포함되어있는 경우,
해당 부분을 '0'으로 치환하고 count해주었다.
또한, 해당 부분은 이미 확인을 한 부분이기때문에 i++로 다음 부분부터 확인해주었다.
(dz=는 i+=2)마지막으로, for문을 한번 더 이용해 위 과정을 거친 알파벳의 0이 아닌 부분을 카운트한다.
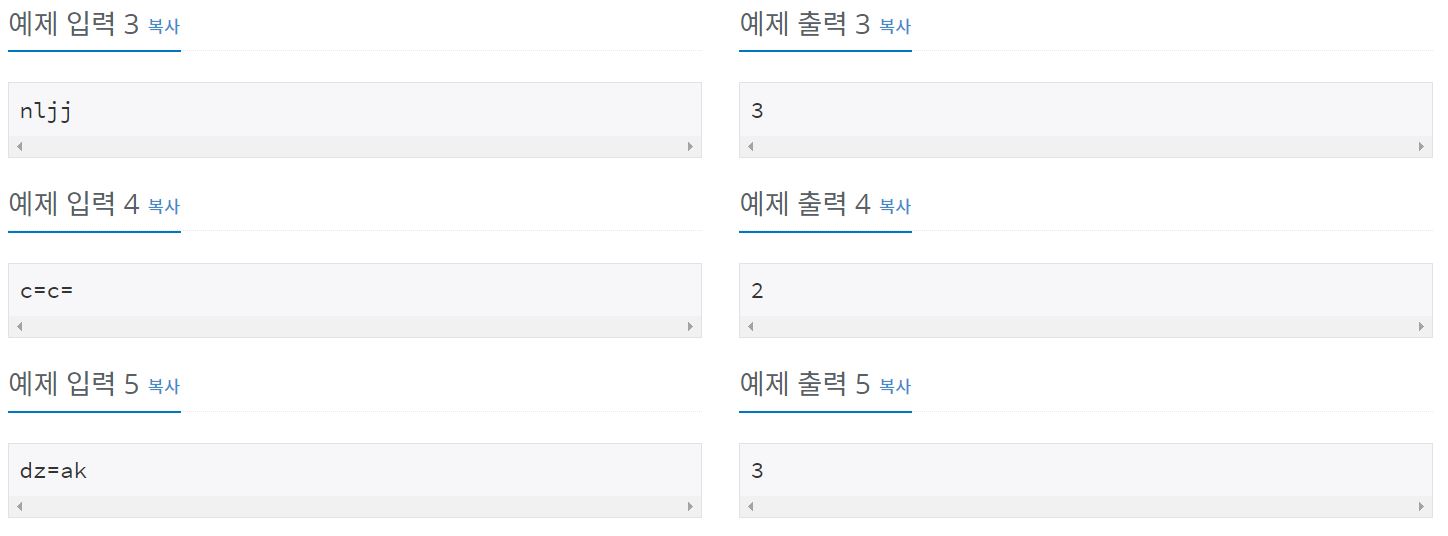
예제 입력 1(ljes=njak)의 경우를 위 코드에 대입해보면,
lj, s=, nj 라는 특수한 경우의 크로아티아 알파벳이있고, 이를 0으로 치환하게 된다.
이때의 count = 3이다.즉, 알파벳은 00e0000ak가 되고,
0이 아닌 부분을 카운트하므로, count = 3+3 = 6 가 된다.
오늘 한 크로아티아 알파벳은 코드는 길었지만 비교적 간단했던 문제였다고 생각된다. 😊
다른 분들의 코드를 보니, 나처럼 그냥 8개의 경우를 나누어주지 않고, c=, c-인 경우가 있기 때문에
첫 글자가 c인 경우, 그 안에 =, -인 경우로 나누어서 코드를 구현하신 분들도 많이 계셨다.
코드를 짜고 나서 다른 분들의 코드를 보고 여러가지 구현방법을 보는것도 또 하나의 공부가 되는 것 같다. 😌
'코딩테스트 > 📗 백준 (BOJ)' 카테고리의 다른 글
| [C] 백준 11170번 0의 개수 (0) | 2021.07.28 |
|---|---|
| [C++] 백준 11004번 K번째 수 (0) | 2021.07.27 |
| [C] 백준 14467번 소가 길을 건너간 이유 1 (0) | 2021.07.24 |
| [C++] 백준 1436번 영화감독 숌 (0) | 2021.07.23 |
| [C] 백준 14405번 피카츄 (0) | 2021.07.22 |



